Description
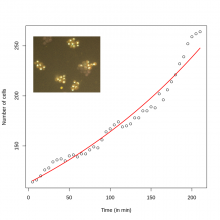
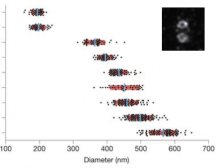
This one example workflow from the Cell Profiler(CP) Examples . CP is commonly used to count cells or other objects as well as percent-positives, by measuring the per-cell staining intensity. This pipeline shows how to do both of these tasks, and demonstrates how various modules may be used to accomplish the same result.
In a few words, it used the IdentifyPrimaryObject module of CellProfiler to detect nuclei from a channel (e.g DAPI), then again the same module on another channel to detect another probe (e.g some particular histone) .
Then objects (nuclei) are related to the second object (Histone), to create a parent child-relation ship: where nuclei can have histone has child. Nuclei are then filtered according to the property of having histone (positive) or not having histone (negtiveobject) related to them. If needed, nuclei can be expanded in order to include touching object rather than object inside only.
The percentage of positive nuclei vs total number of nuclei can then be computed using the CalculateMath Module.