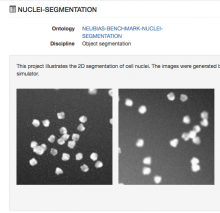
Description
CellProfiler is free, open-source software for quantitative analysis of biological images.
CellProfiler is designed to enable biologists without training in computer vision or programming to quantitatively measure cell or whole-organism phenotypes from thousands of images automatically. The researcher creates an analysis pipeline from modules that find cells and cell compartments, measure features of those cells to form a rich, quantitative dataset that characterizes the imaged site in all of its heterogeneity. CellProfiler is structured so that the most general and successful methods and strategies are the ones that are automatically suggested, but the user can override these defaults and pull from many of the basic algorithms and techniques of image analysis to solve harder problems. CellProfiler is extensible through plugins written in Python or for ImageJ. Strengths: Cells, Neurons, C. Elegans, 2D Fluorescent images, high-throughput screening, phenotype classification, multiple stains/site, interoperability, extensibility, machine learning, segmentation Limitations: largely limited to 2D, not well suited to manually-guided analysis or content review, image size limitations