
Cell or particle Counting and scoring stained objects using CellProfiler
Type
Execution Platform
Implementation Type
Programming Language
Supported image dimension
Interaction Level
License/Openness
Description
This is a Jupyter notebook demonstrating the run of a code from IDR data sets by loading a CellProfiler Pipeline
The example here is applied on real data set, but does not correspond to a biological question. It aims to demonstrate how to create a jupyter notebook to process online plates hosted in the IDR.
It reads the plate images from the IDR.
It loads the CellProfiler Pipeline and replace the reading modules used to read local files from this defaults pipeline by module allowing to read data remotely accessible.
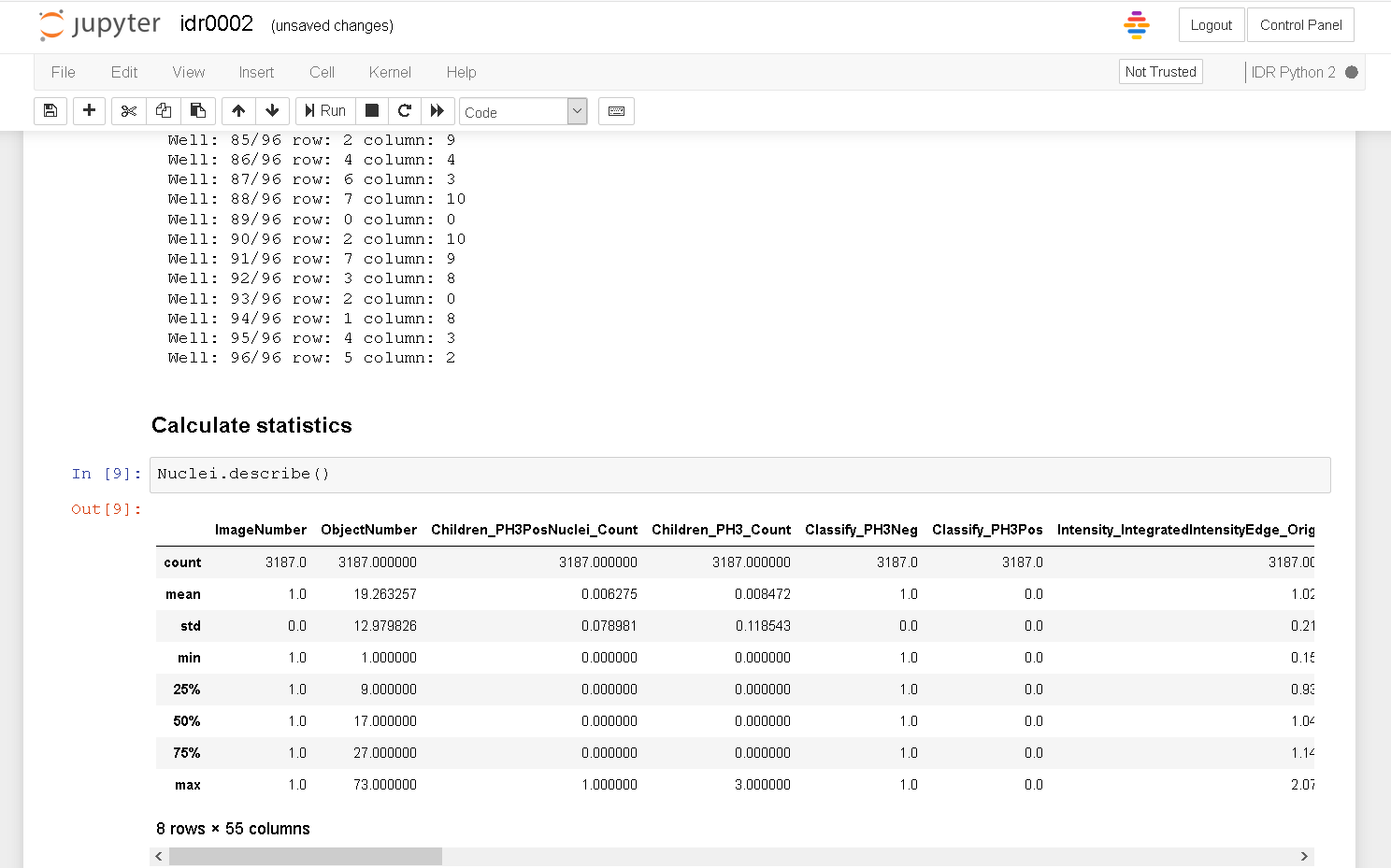
It creates a CSV file and displays it in the notebook.
It makes some plot with Matplotlib.
has function
has topic
Entry Curator
Post date
08/16/2018 - 13:11
Last modified
10/18/2018 - 17:35